



这是此工作流程的较旧版本。
我找不到编辑按钮,我找不到删除此工作流程的方法。 So I guess it remains.
The other version is more fully automated with automatic captions and naming of the output files.
What this workflow does
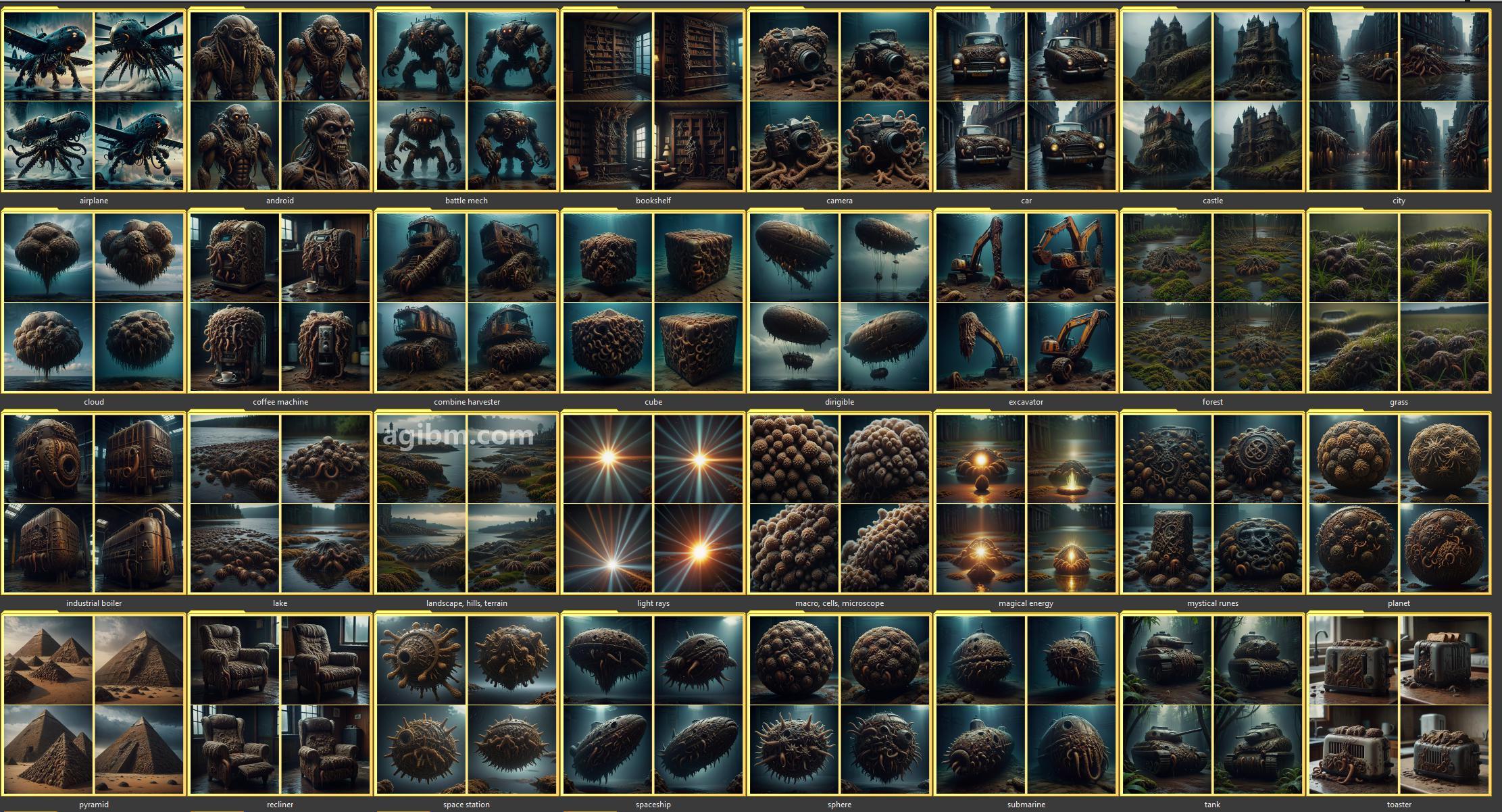
👉 Uses a reference image to set a “style”, and then creates a full dataset suitable for training a style from.
How to use this workflow
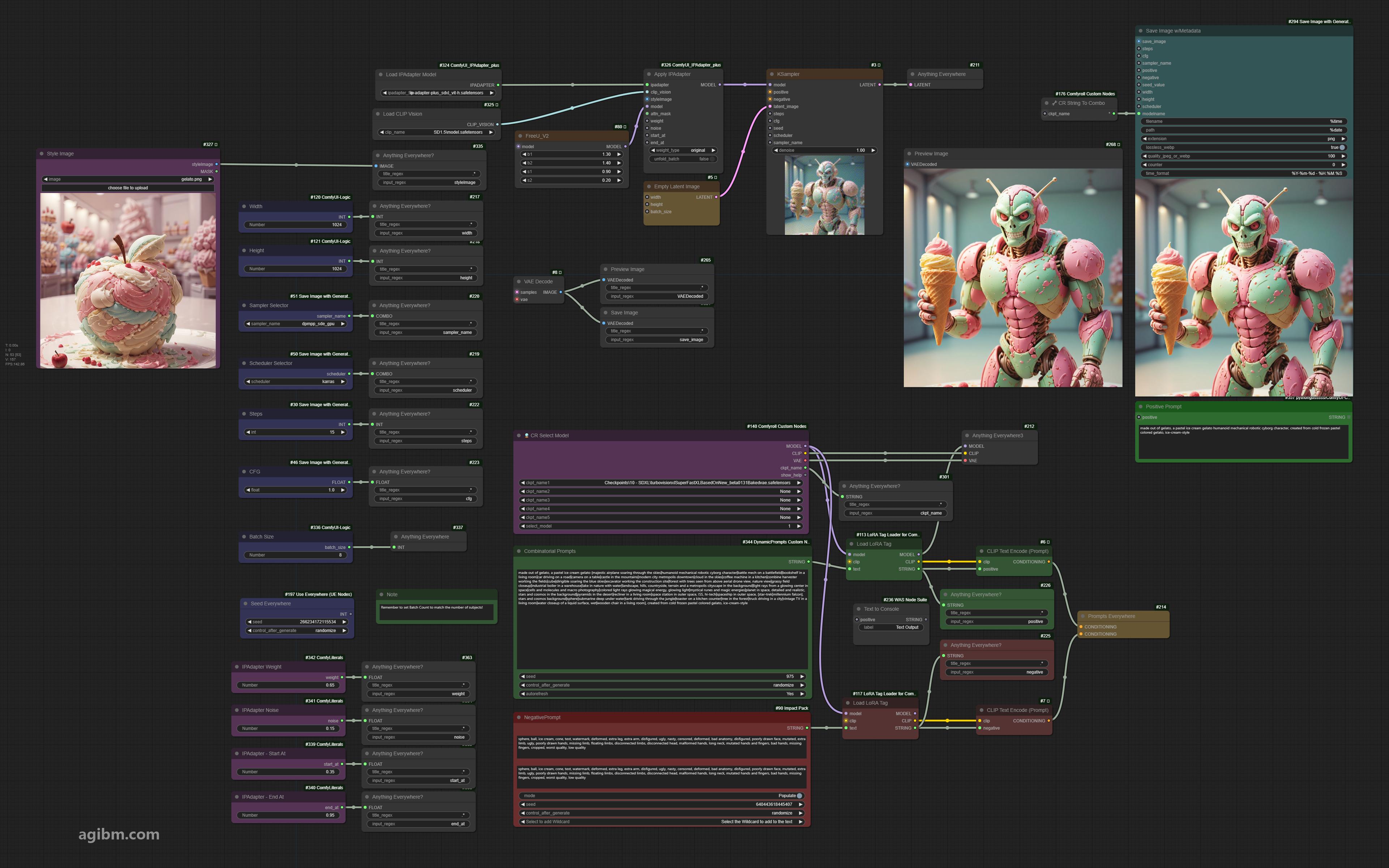
👉 Choose a checkpoint of choice.我一直在使用turbovisionxl(中间)
👉在样式图像部分添加图像(左上方)
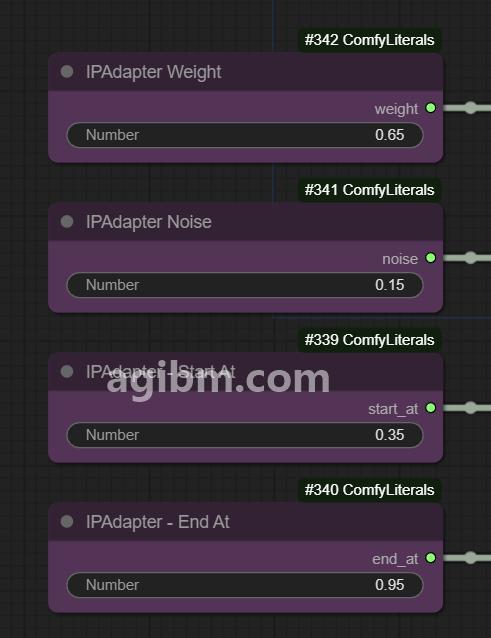
👉调整iPadapter设置,这需要一些调整才能使您的输入映像的正确数量和时间安排(左下)
</p </p </p </p.匹配主题的数量!对于演示提示中的示例概念是37。
忽略红色“缺失”框提示的左侧。这只是一个文本说明,可以设置批量计数以匹配主题的数量。
有关此工作流程的提示
<您可能会得到一些不良的变化,您可能需要更改设置,并完全更改设置的提示
以前的提高文件
pafination
p> p> p> p> p> p> p> p> p> p> p> p> image
👉 Allow multiple/random images to be used as input
👉 Get stronger difference in the output, right now the outputs feel more like variation seeds rather than their own generations
Update:
I sat down and updated the workflow to automatically name the files according to the subject, as well as output a pre-filled caption file.它确实需要一个节点集来接收到输出的更新,因此直到将我的本地代码推到保存文件名节点之前,它才能起作用。